
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 백준
- 회고
- 성능최적화
- GPU
- FE
- wil
- webGPU
- 개발 공부
- 보안
- 개발자
- frontend
- rust
- 항해
- 항해 플러스 프론트엔드
- 성장일지
- 자바스크립트
- 알고리즘
- React Query
- 프론트엔드
- 항해 플러스
- 테스트 코드
- 항해99
- 항해플러스
- 분기 회고
- 개발공부
- 리뷰
- React
- typescript
- javascript
- naver
- Today
- Total
느릿늘있
[TIL] Naver FE News 2024-01 본문
[TIL] Naver FE News는 Naver FE 팀에서 매월 첫째주 수요일에 업로드하는 FE 관련 이슈들을 팔로우 하면서 관심있는 내용을 학습하고 정리하는 컨텐츠입니다. [ https://github.com/naver/fe-news ]
1. What Every Developer Should Know About GPU Computing (foot translated)
1. 모든 개발자가 알아야하는 GPU 컴퓨팅 (발번역)
https://codeconfessions.substack.com/p/gpu-computing
What Every Developer Should Know About GPU Computing
A primer on GPU architecture and computing
codeconfessions.substack.com
Intro
대부분의 개발자들은 CPU 그리고 절차적인(sequential) 프로그래밍에는 익숙하다. 왜냐하면 그들은 CPU에 맞춰서 코드를 짜왔기 때문이다. 하지만 많은 이들이 그들을 더 특별하게 만들어줄 수 있는 GPU의 내부 동작 원리에는 관심이 없다. 지난 몇년을 돌아보면, 딥러닝에 GPU가 널리 사용되면서 그 중요성이 폭발적으로 증가했다. 따라서, 현 시대의 개발자들에게 GPU가 어떻게 돌아가는 지 정도를 아는 것은 기본 소양이 되고 있다. 이 글의 목표는 개발자 당신에게 그 배경 지식을 전달하는 것이다.
이 글의 대부분은 Hwu et al.의 4번째 편집본인 “Programming Massively Parallel Processors"에 기반한다. 이 책에서 Nvidia의 GPU들을 중심으로 서술하고 있기 때문에 나도 그럴테지만 근본에 있는 컨셉은 모든 GPU에 통용한다는 사실을 기억해달라.
CPU와 GPU의 비교
CPU와 GPU의 비교에서부터 시작해봅시다. 이 또한 쉬운 영역은 아니기에 하나의 섹션에서 다 다루기는 어렵습니다. 그래서 몇가지 포인트들을 가져왔습니다.
가장 중요한 차이점은 CPU와 GPU의 설계 목표(design goals)입니다. CPU는 (멀티코어로 병렬처리를 지원하기는 하지만) 직렬적이고 순차적인 처리를 잘 하기 위해 설계되었습니다. CPU의 성능이란 이 직렬형 처리를 얼마나 빠르고 정확하게 하느냐에 달려있습니다.
GPU는 반대로 병렬적이고 massive한 처리를 잘 하기 위해 설계되었습니다. 이를 위해 지연(latency)를 허용합니다. 이러한 설계 목적은 그들이 비디오 게임, 그래픽, 산술 계산, 딥러닝을 지원하는 것을 목표로 합니다. 이러한 작업들은 엄청난 처리량을 요구하지만 복잡한 산술보다는 선형 대수학과 같은 단순한 산술을 요구합니다.
예를 들어보겠습니다. CPU는 1+1을 GPU보다 빠르게 처리합니다(low instruction latency). 하지만 1+1, 2+2, 3+3,.... 이런 식으로 백만, 천만 단위의 계산을 요구하게 되면 GPU가 훨씬 빠르게 처리할 것입니다. (병렬로 처리하니까)
아래 이미지는 CPU와 GPU의 설계 구조를 비교한 것입니다.

이미지에서 볼 수 있듯이, CPU에는 명령 지연 시간을 줄이기 위한 제어 장치와 대규모 캐시 공간이 있습니다. 이에 따라 Core의 공간이 작고 산술연산 장치(ALU)가 칩의 많은 영역을 차지하지 못합니다. 반대로 GPU는 산술연산 장치(ALU)에 최대한 많은 자원을 할애합니다.
지연 허용과 높은 처리량
이렇게 GPU는 latency를 허용하면서도 어떻게 높은 성능을 제공할 수 있는 걸까요? 정답은 GPU의 수 많은 쓰레드 갯수와 엄청난 컴퓨팅 파워에 있습니다. GPU는 그 많은 쓰레드들이 쉴틈없이 일하도록 효율적인 스위칭 작업을 수행합니다. 개별 쓰레드의 latency가 있을지라도 모든 쓰레드가 쉴틈없이 일하게 만듦으로써 높은 성능을 내는 것입니다. 보다 자세한 내용은 커널이 GPU를 어떻게 사용하는 지 알아보는 섹션에서 말씀드리겠습니다.
GPU의 구조
GPU는 SM(스트리밍 멀티프로세서)의 배열 형태로 구성됩니다. 이러한 SM은 여러 개의 스트리밍 프로세서, 코어 또는 스레드로 구성됩니다.

각 SM의 메모리는 모든 코어에서 공유하는 공유메모리의 제한된 양만을 사용하는 on-chip 메모리를 갖고 있습니다. (그림의 Memory) 그리고, SM의 제어 장치(Control)의 리소스는 모든 코어에서 공유됩니다. 또한, 각 SM에는 하드웨어 기반의 스레드 스케쥴러가 장착되어 있습니다. 그 밖에도 텐서 코어와 같은 기타 가속 컴퓨팅 유닛이 있습니다. 이 중에서 메모리부터 한 번 자세히 알아봅시다.
GPU 메모리 구조
GPU는 계층형 구조를 가지고 있고 각각이 특정 역할을 갖고 있기 때문에 다소 복잡해 보이더라도 한 번 천천히 분석해봅시다.

- Registers : SM 하나가 보통 6만 개 이상(모델마다 다름)의 Register를 가지고 있습니다. 이 Register들은 코어 간에 공유되며 스레드의 요청에 따라 동적으로 할당됩니다. 이 때, 스레드에 할당된 Register는 다른 스레드에서 접근할 수 없습니다.
- Constant Cahes : 코드에서 사용하는 상수 데이터를 캐싱하는 공간입니다. GPU는 개발자가 Constant로 선언한 변수에 대해 이 캐싱 영역에 저장합니다.
- Shared Memory : 각 SM에는 작지만 빠른 SRAM 메모리인 Shared Memory가 있습니다. 이는 스레드 간 데이터 공유를 위해 설계되었습니다. 특정 스레드에서 Global Memory 데이터를 Shared Memory 공간으로 가져오면 다른 스레드는 이를 공유합니다. 이를 잘 활용하면 Global Memory 부하를 줄이고 커널 성능을 향상시킬 수 있습니다.
- L1 Cache : L2 Cache에서 자주 사용하는 데이터를 저장해두는 L1 Cache가 있습니다.
- L2 Cache : 모든 SM이 공유하는 캐시 공간입니다. Global Memory에서 자주 사용하는 데이터를 저장해둡니다. 여기서 중요한 점은 SM이 해당 데이터를 L1, L2, Global 어디에서 가져오는 지 알 수 없다는 점입니다. 캐싱은 SM의 동작과 상관 없이 발생하고 SM은 Shared Memory 데이터가 아닌 모든 데이터를 Global Memory에서 가져온다고 간주하며 이는 CPU의 캐시가 동작하는 방식과 거의 동일합니다.
- Global Memory : off-chip memory인 global memory는 높은 용량과 대역폭을 가지고 있는 DRAM입니다. SM이 global memory에 접근하는 것은 latency가 상당한 작업이지만 위에서 이를 보조하는 on-chip 메모리들이 있고 그 밖에도 다른 컴퓨팅 유닛들이 이 latency를 감추기 위해 존재합니다.
이렇게 GPU의 가장 중요한 요소인 메모리에 대해 알아봤습니다. 이제 코드가 실행될 때, 이 요소들이 어떻게 동작하는 지 조금만 더 깊게 알아보도록 합시다!
CUDA 커널과 스레드 블록에 대한 간략한 소개
GPU가 커널을 실행하는 방법을 이해하려면 먼저 커널이 무엇인지, 어떻게 구성되는 지 이해해야 합니다. CUDA는 Nvidia에서 개발한 GPU 프로그램 작성 용 인터페이스입니다. 사용법은 C/C++ 함수와 유사하며 이 함수들을 커널이라고 합니다. 커널은 함수의 매개변수로 제공되는 벡터값에 대해 병렬적으로 동작합니다. 병렬적으로 동작하기 위해 GPU는 많은 수의 스레드를 운용해야하고 이는 그리드라고 하는 요소에 의해 가능해집니다. (그리드는 여러 스레드 블록을 갖고 있고 스레드 블록은 여러 스레드를 갖고 있다.)

구현의 레벨에서는 두 부분으로 나누어 볼 수 있습니다. 첫 번째는 CPU에서 실행되는 host code인데, 이는 데이터를 불러오고 GPU에 메모리를 할당하고 그리드로 구성된 커널을 구동합니다.

두 번째는 GPU에서 실행되는 device code인데, 이는 실제 커널 함수들을 정의합니다.
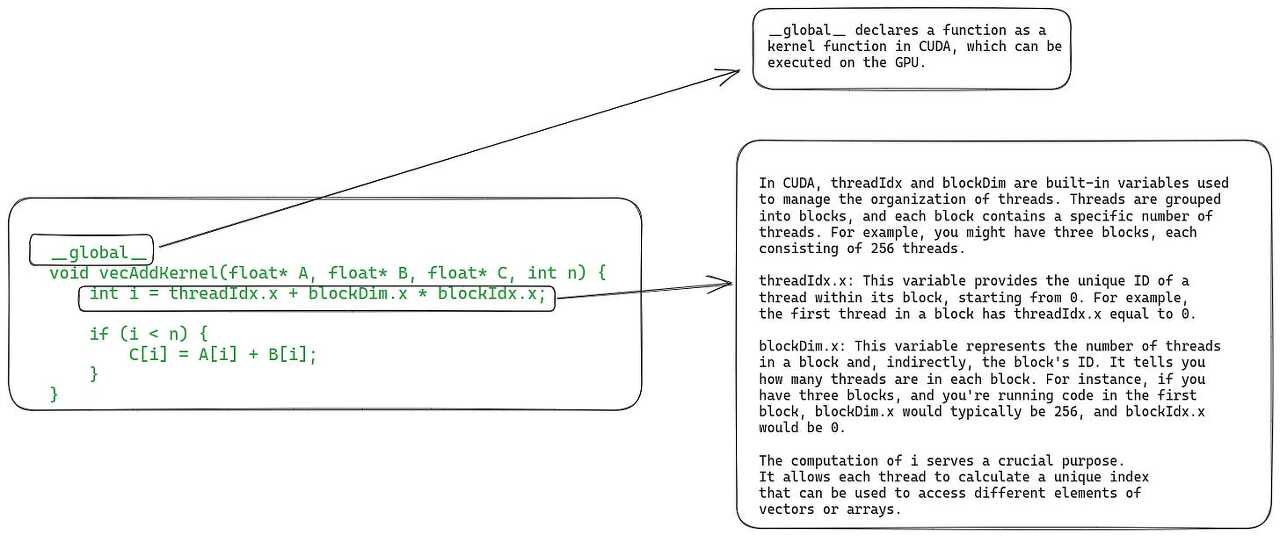
이미지가 복잡하게 있기는 한데 CUDA를 아는 것이 이 글의 목적은 아니니까 넘어가도록 합시다!
GPU에서 커널을 실행하는 단계
1단계. host(CPU)에서 device(GPU)로 데이터 복사
커널 실행을 스케쥴링하기 전에 필요한 모든 데이터를 CPU에서 GPU의 global memory로 복사해야 합니다. 최신 GPU 하드웨어에서는 통합 가상(virtual) 메모리를 사용하여 CPU의 메모리를 직접 읽을 수도 있습니다.
2단계. SM(스트리밍 멀티프로세서) 의 스레드 블록 스케쥴링
GPU는 필요한 모든 데이터를 메모리에 저장한 이후, 스레드 블록을 SM에 할당합니다. 하나의 스레드 블록 내 모든 스레드는 하나의 SM에서 동시에 처리됩니다.(하나의 SM은 여러 스레드 블록을 동시에 실행함) 이게 가능하려면 GPU가 스레드 실행 전에 해당 스레드에 대한 리소스를 반드시 미리 준비해두어야 한다는 사실을 기억해주세요!

당연하게도 SM의 수는 한정적이기 때문에 반드시 모든 블록이 동시에 즉시 실행되도록 할당되지는 않습니다. 따라서 GPU도 대기 목록을 관리하고 어떤 블록이든 실행이 완료되면 GPU는 실행 대기 목록에서 순차적으로 다음 작업을 할당합니다.
3단계. Single Instruction Multiple Threads (SIMT) and Warps
warp는 쉽게 말해 32개의 쓰레드 그룹입니다. 이 warp로 묶인 쓰레드들은 processing block이라는 코어 세트에 묶여서 실행됩니다. 이 warp는 SM에 의해 활용될 때, 동일한 동작을 서로 다른 데이터에 대해서 실행하는 역할을 담당합니다. 즉, 같은 덧셈이라는 동작을 수행하더라도 어떤 쓰레드는 1+1을, 어떤 쓰레드는 2+2를 수행할 때 활용합니다. 이러한 동작 방식을 우리는 Single Instruction Multiple Threads (SIMT)라고 부릅니다. (CPU의 Single Instruction Multiple Data (SIMD)와 유사하다고 함 + independent thread scheduling이라는 채신 기술도 있으니 관심 있으면 알아보길 바람).
4단계. warp 스케쥴링과 지연 허용
SM은 사용할 수 있는 실행 단위(execution units)가 제한되어 있기 때문에 모든 쓰레드 블록들이 warp 처리에 할당되더라도 그 중 일부만이 동작합니다. 시간이 오래 걸리는 작업들은 워프를 기다리게 만듭니다. 하지만, 모든 warp가 일순간 동작하지 않기 때문에 시간이 오래 걸리는 경우에는 쉬고 있는 워프에게 다음 작업을 바로 할당할 수 있습니다. 이를 통해 GPU는 컴퓨팅 자원을 최대로 활용하고 높은 처리량을 짧은 시간 안에 제공할 수 있습니다.
5단계. 결과값을 device(GPU)에서 host(CPU)로 복사
마참내, 모든 쓰레드가 작업을 마치면 마지막 단계에는 그 결과를 host memory(CPU)로 복사합니다.
이렇게 GPU의 일반적인 동작 원리에 대해서 모두 알아봤습니다.
자원 분할(Resource Partitioning)과 점유율(occupancy)
GPU 리소스의 활용도는 점유율이라고 부르는 SM에 할당된 워프 수와 SM이 한 번에 최대로 지원할 수 있는 워프 수의 비율을 지표로 사용합니다. 최대 처리량을 위해서는 점유율 100%를 달성하면 되지만 현실적으로 이는 불가능합니다. 그래도 최대 점유율을 달성하기 위해 리소스를 동적으로 분할하게 되는데 글에서 몇 가지 예시를 들고 있지만 어떻게 하면 되는 지는 나오지 않기에 세부 내용은 생략하겠습니다. 중요한 것은 현명하게 이 점유율을 조정해주어야 한다는 것입니다.
요약
- A GPU consists of several streaming multiprocessors (SM), where each SM has several processing cores.
- There is an off chip global memory, which is a HBM or DRAM. It is far from the SMs on the chip and has high latency.
- There is an off chip L2 cache and an on chip L1 cache. These L1 and L2 caches operate similarly to how L1/L2 caches operate in CPUs.
- There is a small amount of configurable shared memory on each SM. This is shared between the cores. Typically, threads within a thread block load a piece of data into the shared memory and then reuse it instead of loading it again from global memory.
- Each SM has a large number of registers, which are partitioned between threads depending on their requirement. The Nvidia H100 has 65,536 registers per SM.
- To execute a kernel on the GPU, we launch a grid of threads. A grid consists of one or more thread blocks and each thread block consists of one or more threads.
- The GPU assigns one or more blocks for execution on an SM depending on resource availability. All threads of one block are assigned and executed on the same SM. This is for leveraging data locality and for synchronization between threads.
- The threads assigned to an SM are further grouped into sizes of 32, which is called a warp. All the threads within a warp execute the same instruction at the same time, but on different parts of the data (SIMT). (Although newer generations of GPUs also support independent thread scheduling.)
- The GPU performs dynamic resource partitioning between the threads based on each threads requirements and the limits of the SM. The programmer needs to carefully optimize code to ensure the highest level of SM occupancy during execution.
- GPU는 여러 SM(스트리밍 멀티프로세서)으로 구성되어 있으며, 각 SM에는 여러 processing core가 있습니다.
- HBM 또는 DRAM인 off chip 글로벌 메모리가 있고 칩과 SM의 거리가 멀면 지연이 더 발생합니다.
- off chip 캐시인 L2와 on chip 캐시인 L1이 있습니다. 이들의 동작 방식은 CPU와 유사합니다.
- 각 SM에는 core간 공유되는 소량의 공유메모리가 있습니다. 일반적으로 쓰레드는 글로벌 메모리를 매번 이용하는 것이 아닌 이 공유 메모리에 데이터를 넣어두고 재사용합니다.
- 각 SM에는 스레드간 분할된 수많은 레지스터가 있습니다. (Nvidia H100에는 SM당 65,536개의 레지스터가 있습니다.
- GPU에서 커널을 실행하기 위해 그리드를 실행하고 그리드는 하나 이상의 스레드로 구성된 스레드 블록으로 구성됩니다. (그리드 > 쓰레드 블록 > 쓰레드)
- GPU는 데이터의 지역성과 쓰레드간 동기화를 보장하기 위해, 블록 내의 모든 쓰레드를 동일한 SM에서 할당하고 실행합니다.
- SM에 할당된 쓰레드는 32개씩 그룹화되어 warp라고 불립니다. warp 내의 모든 쓰레드는 동일한 명령을 동시에 실행하지만 서로 다른 데이터를 바라봅니다.(SIMT)
- GPU는 각 스레드의 요구사항과 SM의 한계를 기반으로 동적으로 리소스를 분할합니다. 프로그래머는 최고 수준의 SM 점유율을 보장하기 위해 코드를 신중하게 최적화해야 합니다.
'개발공부' 카테고리의 다른 글
| 우당탕탕 RUST 도전기 (1) (0) | 2024.06.23 |
|---|---|
| [TIL] Naver FE News 2024-02 (0) | 2024.02.17 |
| [TIL] Naver FE News 2023-11 (0) | 2023.12.31 |
| [기록] Nest.js의 세부 동작 과정에 관한 좋은 글 (0) | 2023.10.17 |
| [TIL] Naver FE News 2023-10 (0) | 2023.10.13 |


